Яндекс и Google не заинтересованы в том, чтобы были люди, которые умеют выводить сайты на первые места в поисковых системах. Им выгодно, чтобы люди вкладывались в контекстную рекламу, а seo для них оставалось черной магией или танцами вокруг костра с бубном. Это логично, ведь по данным самого Яндекса доход компании с рекламы составляет 15,8 млрд рублей за первый квартал 2016 года, а это 96% от дохода всей компании. Вы только вдумайтесь, Яндекс живёт за счёт рекламы!
Поэтому, в блоге Яндекса и Google для вебмастеров довольно мало практической информации по SEO. Конечно, там подробно расписано про заполнение title, robots.txt, микроразметку и т.д., но воздействие только на эти базовые вещи уже не поможет Вам попасть в ТОП.
Как тогда продвигают сайты seoшники? У каждого из нас есть практический опыт, мы много экспериментируем и анализируем, и через несколько лет практики, мы уже сами понимаем, что одни факторы хорошо работают, другие обязательно должны быть, а третьими можно пренебречь для данной тематики. Т.е. мы делаем для заказчика то, что дало нам результаты на десятках других проектов.
Всё же, мы имеем следующие «библии» для российских сеошников, которые каждый должен знать наизусть:
- Техническая документация Яндекса
- Яндекс Помощь вебмастеру
- Руководство Google по поисковой оптимизации для начинающих
- Pdf руководство от Google для начинающих
Схематично работу поисковой системы можно разбить на 3 этапа:
1) Краулинг
Составление списка всех существующих страниц: робот - краулер собирает список всех страниц в интернете, которые необходимо проиндексировать. В самом начале в алгоритм робота вручную заносились самые крупные сайты интернета, затем, робот переходит по всем ссылкам, которые встречает на пути, и добавляет новые сайты в очередь на индексирование.
2) Индексирование
Робот - индексатор анализирует содержимое всех сайтов, которые ему предоставляет робот - краулер. Каждая страница анализируется по многим параметрам, в процессе индексирования. Индексирование - процесс сбора, сортировки и хранения информации.
Одна из самых основных задач робота на данном этапе – выделить все слова из html кода. Для этого поисковые системы выполняют следующие действия:
- Выделение чистого текста – обрезаются все html теги.
- Выборка слов. На данном этапе нужно весь текст преобразовать в массив слов. Разделителями слов будут являться пробелы и знаки препинания.
- Лингвистическая обработка – процесс преобразования каждого слова из текста к начальной грамматической форме. Этот алгоритм называется лемматизацией. Поисковые системы в процессе лингвистической обработки сталкиваются со следующими трудностями: во-первых, есть слова, которые при одинаковом написании имеют различные начальные формы. Пример из русского языка: печь (русская) / печь (пироги). Во-вторых. Не для всех слов существует начальная форма. В третьих, каждое слово в русском языке обладает большим количеством словоформ, и нужно проработать целую систему словоформ для каждого существующего слова.
- Внесение в индекс.
На этом этапе в задачу робота входит выявление всех слов, которые встречаются в документе. Затем, нужно сделать соответствие запрос - документ. Для этого есть 2 способа:
А) Прямой индекс: для каждой страницы составляется список фраз, которые на ней встречаются.
Пример:
|
Документ |
Слова |
|---|---|
|
Документ 1 |
наша, Таня, громко, плачет |
|
Документ 2 |
уронила, в, речку, мячик |
|
Документ 3 |
тише, Танечка, не, плачь, |
|
Документ 4 |
не, утонет, в, речке, мяч |
Б) Инвертированный индекс: для каждой фразы составляется список страниц, на которых они встречаются.
|
Слово |
Документы |
|---|---|
|
в |
Документ 2, Документ 4 |
|
громко |
Документ 1 |
|
мяч |
Документ 2, Документ 4 |
|
наша |
Документ 1 |
|
не |
Документ 3, Документ 4 |
|
плакать |
Документ 1, Документ 3 |
|
речка |
Документ 2, Документ 4 |
|
Таня |
Документ 1, Документ 3 |
|
тише |
Документ 3 |
|
уронить |
Документ 2 |
|
утонуть |
Документ 4 |
Естественно, поисковые системы используют в своей работе именно инвертированный индекс.
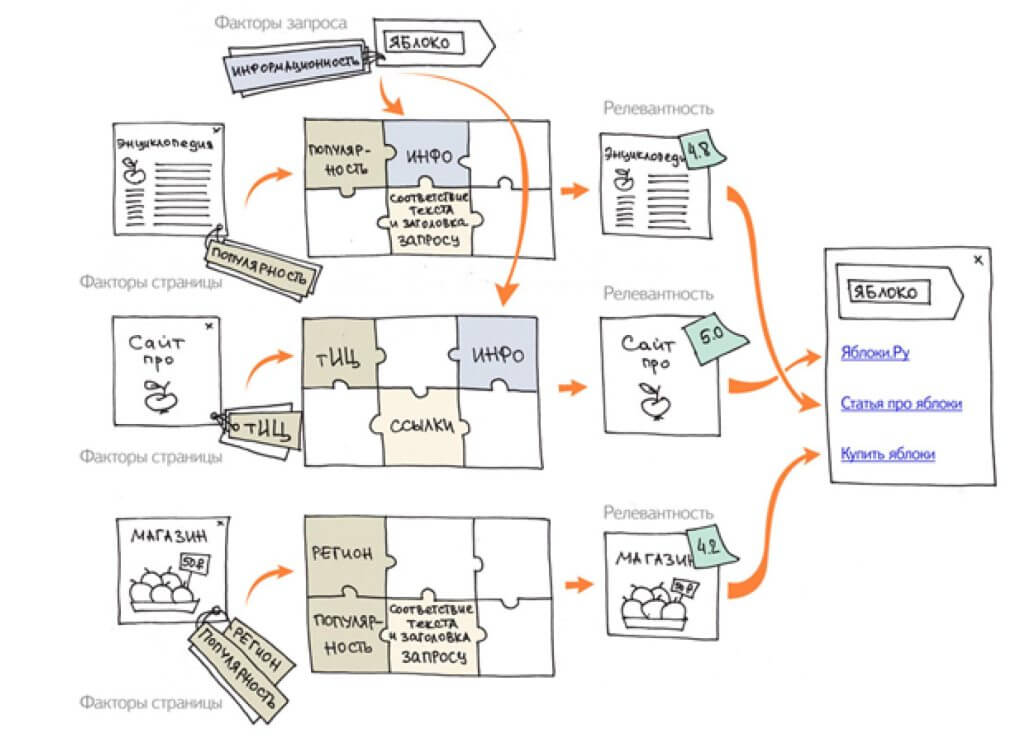
3) Ранжирование
Третий тип роботов на основе проиндексированных данных составляет рейтинг сайтов, какой же из них наилучшим образом отвечает на запрос.
Поисковые системы сейчас используют алгоритмы машинного обучения:
- Матрикснет (Яндекс)
- Google RankBrain (часть основного поискового алгоритма «Колибри»)
В июле 2018 года Яндекс объявил об использовании нового алгоритма машинного обучения CatBoost
Давайте разберём процесс машинного обучения на простом примере. Когда человеку дают попробовать яблоко, ему легко сказать, вкусное ли это яблоко или нет. А вот робот не может сказать, будет ли яблоко вкусным для людей. Но робот может для любого яблока вычислить процент содержания кислот или воды. Для машинного обучения необходима база асессоров (выборка людей, каждому из которых дадут попробовать несколько яблок, и человек должен по каждому фрукту сказать, считает ли он его вкусным, или нет).
После того, как робот получил от асессоров статистические данные, он ищет закономерности в их ответах. Например, он может заметить, что все яблоки, которые большинство людей сочли вкусными процент содержания кислот не превышает 0,9%, а процент содержания воды более 85%. И тогда программа может предположить, что все яблоки с такими характеристиками будут вкусными для людей.
Аналогично работают алгоритмы и в случае с качеством ответов на поисковые запросы. В качестве асессора Яндекса может быть каждый из нас, для этого достаточно зайти на сервис Толока. Там за деньги Вы сможете за деньги отвечать на вопросы Яндекса и помогать ему обучаться.
Тем, кто хочет погрузиться глубже в алгоритмы машинного обучения Яндекса, рекомендую видеозаписи курсов ШАД (школа анализа данных), которые находятся в открытом доступе.



Никита Селиванов
Остались вопросы? Пиши в комментарии, я отвечу!